Server Clash: DELL's Quad Opteron DELL R815 vs HP's DL380 G7 and SGI's Altix UV10
by Johan De Gelas on September 9, 2010 7:30 AM EST- Posted in
- IT Computing
- AMD
- Intel
- Xeon
- Opteron
Real World Power
In the real world you do not run your virtualized servers at their maximum just to measure the potential performance. Neither do they run idle. The user base will create a certain workload and expect this workload to be performed with the lowest response times. The service provider (that is you!) wants the server to finish the job with the least amount of energy consumed. So the general idea behind this new benchmark scenario is that each server runs exactly the same workload and that we then measure the amount of energy consumed. It is similar to our previous article about server power consumption, but the methodology has been enhanced.
We made a new benchmark scenario. In this scenario, we changed three things compared to the vApus Mark II scenario:
- The number of users or concurrency per VM was lowered significantly to throttle the load
- The OLTP VMs are omitted
- We ran with two tiles
vApus Mark II loads the server with up to 800 users per second on the OLAP test, up to 50 users per second on the website, and the OLTP test is performing transactions as fast as it can. The idea is to give the server so much work that it is constantly running at 95-99% CPU load, allowing us to measure throughput performance quite well. vApus Mark II is designed as a CPU/memory benchmark.
To create a real world “equal load” scenario, we throttle the number of users to a point where you typically get somewhere between 30% and 60% CPU load on modern servers. As we cannot throttle our OLTP VM (Swingbench) as far we as know, we discarded the OLTP VM in this test. If we let the OLTP test run at maximum speed, the OLTP VM would completely dominate the measurements.
We run two tiles with 14 vCPUs (eight vCPUs for OLAP, three webservers with two vCPUs per tile), so in total 28 virtual CPUs are active. There are some minor tasks in the background: a very lightly loaded Oracle databases that feeds the three websites (one per tile), the VMware console (which idles most of the time), and of course the ESX hypervisor kernel. So all in all, you have a load on about 30-31 vCPUs. That means that some of the cores of the server system will be idleing, just like in the real world. On the HP DL380 G7, this “equal workload” benchmark gives the following CPU load graph:
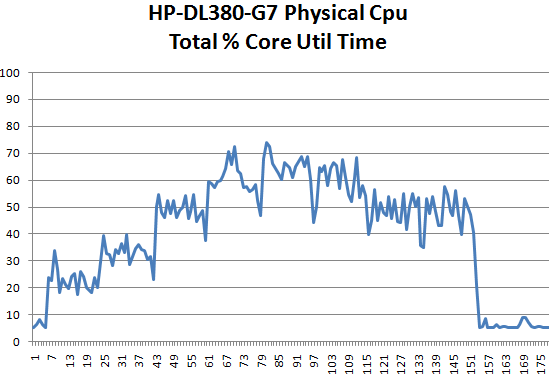
On the Y-axis is CPU load, and on the X-axis is the periodic CPU usage. ESXtop was set up to measure CPU load every five seconds. Each test was performed three times: two times to measure performance and energy consumption, and the third time we did the same thing but with extensive ESXtop monitoring. To avoid having the CPU load in the third run much higher than the first two, we measured every five seconds. We measure the energy consumption over 15 minutes.
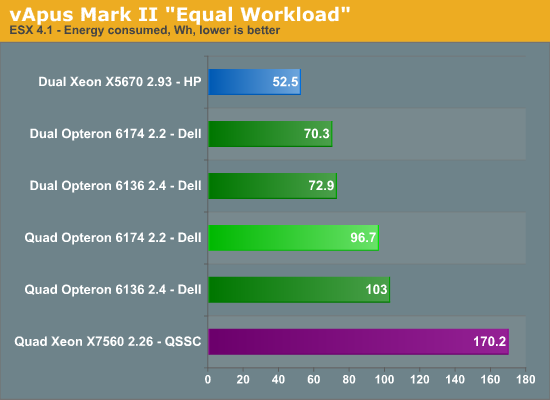
Again, the dual Opteron numbers are somewhat high as we are running them in a quad socket machine. A Dell R715 is probably going to consume about 5% less. If we get the chance, we'll verify this. But even if the dual Opterons are not ideal measurements in comparison to the dual Xeon, they do give us interesting info.
Two Opterons CPUs are consuming 26.5 Wh (96.7 - 70.2). So if we extrapolate, this means roughly 55% (53 Wh out of 97Wh) of the total energy in our quad Opteron server is consumed by the four processors. Notice also that despite the small power handicap of the Opteron (a dual socket server will consume less), it was able to stay close to the Xeon X5670 based server when comparing maximum power (360W vs 330W). But once we introduce a 30-50% load, the gap between the dual Opteron setup and dual Xeon setup widens. In other words, the Opteron and Xeon are comparable at high loads, but the Xeon is able to save more power at lower loads. So there is still quite a bit of room for improvement: power gating will help the “Bulldozer” Opteron drive power consumption down at lower load.
Ok, enough interesting tidbits, who has the best performance per watt ratio?








51 Comments
View All Comments
jdavenport608 - Thursday, September 9, 2010 - link
Appears that the pros and cons on the last page are not correct for the SGI server.Photubias - Thursday, September 9, 2010 - link
If you view the article in 'Print Format' than it shows correctly.Seems to be an Anandtech issue ... :p
Ryan Smith - Thursday, September 9, 2010 - link
Fixed. Thanks for the notice.yyrkoon - Friday, September 10, 2010 - link
Hey guys, you've got to do better than this. The only thing that drew me to this article was the Name "SGI" and your explanation of their system is nothing.Why not just come out and say . . " Hey, look what I've got pictures of". Thats about all the use I have for the "article". Sorry if you do not like that Johan, but the truth hurts.
JohanAnandtech - Friday, September 10, 2010 - link
It is clear that we do not focus on the typical SGI market. But you have noticed that from the other competitors and you know that HPC is not our main expertise, virtualization is. It is not really clear what your complaint is, so I assume that it is the lack of HPC benchmarks. Care to make your complaint a little more constructive?davegraham - Monday, September 13, 2010 - link
i'll defend Johan here...SGI has basically cornered themselves into the cloud scale market place where their BTO-style of engagement has really allowed them to prosper. If you wanted a competitive story there, the Dell DCS series of servers (C6100, for example) would be a better comparison.cheers,
Dave
tech6 - Thursday, September 9, 2010 - link
While the 815 is great value where the host is CPU bound, most VM workloads seem to be memory limited rather than processing power. Another consideration is server (in particularly memory) longevity which is something where the 810 inherits the 910s RAS features while the 815 misses out.I am not disagreeing with your conclusion that the 815 is great value but only if your workload is CPU bound and if you are willing to take the risk of not having RAS features in a data center application.
JFAMD - Thursday, September 9, 2010 - link
True that there is a RAS difference, but you do have to weigh the budget differences and power differences to determine whether the RAS levels of either the R815 (or even a xeon 5600 system) are not sufficient for your application. Keep in mind that the xeon 7400 series did not have these RAS features, so if you were comfortable with the RAS levels of the 7400 series for these apps, then you have to question whether the new RAS features are a "must have". I am not saying that people shouldn't want more RAS (everyone should), but it is more a question of whether it is worth paying the extra price up front and the extra price every hour at the wall socket.For virtualization, the last time I talked to the VM vendors about attach rate, they said that their attach rate to platform matched the market (i.e. ~75% of their software was landing on 2P systems). So in the case of virtualization you can move to the R815 and still enjoy the economics of the 2P world but get the scalability of the 4P products.
tech6 - Thursday, September 9, 2010 - link
I don't disagree but the RAS issue also dictates the longevity of the platform. I have been in the hosting business for a while and we see memory errors bring down 2 year+ old HP blades in alarming numbers. If you budget for a 4 year life cycle, then RAS has to be high on your list of features to make that happen.mino - Thursday, September 9, 2010 - link
Generally I would agree except that 2yr old HP blades (G5) are the worst way to ascertain commodity x86 platform reliability.Reasons:
1) inadequate cooling setup (you better keep c7000 input air well below 20C at all costs)
2) FBDIMM love to overheat
3) G5 blade mobos are BIG MESS when it comes to memory compatibility => they clearly underestimated the tolerances needed
4) All the points above hold true at least compared to HS21* and except 1) also against bl465*
Speaking about 3yrs of operations of all three boxen in similar conditions. The most clear thi became to us when building power got cutoff and all our BladeSystems got dead within minutes (before running out of UPS by any means) while our 5yrs old BladeCenter (hosting all infrastructure services) remained online even at 35C (where the temp platoed thanks to dead HP's)
Ironically, thanks to the dead production we did not have to kill infrastructure at all as the UPS's lasted for the 3 hours needed easily ...